


Table of Contents

There's a certain irony to most articles about information gain in SEO.
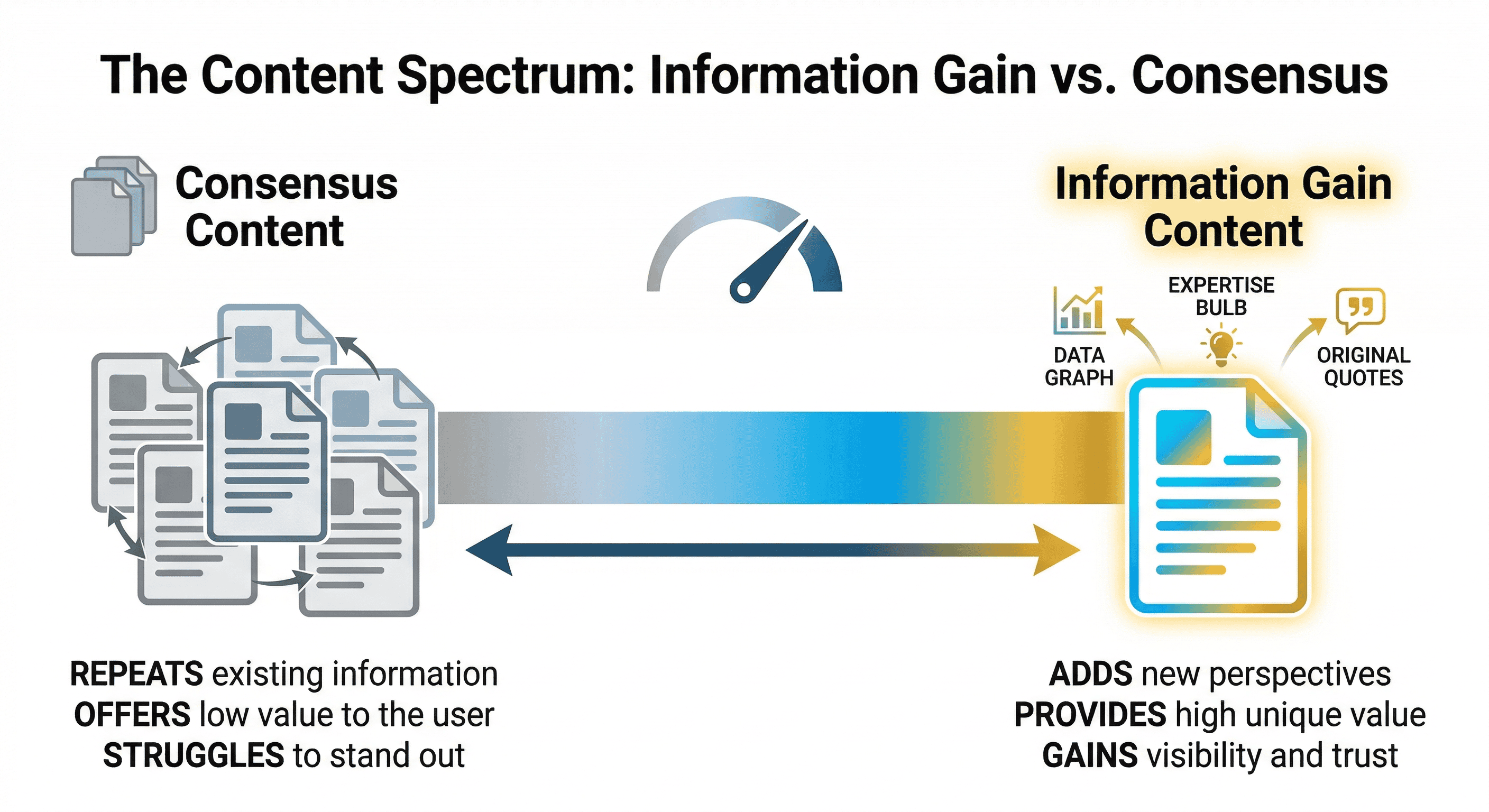
You search for the topic, click through a few results, and read basically the same thing five times: Google has a patent, the patent measures content uniqueness, the skyscraper technique is dead, you should get original data. Great. Thanks. Very helpful.
Those articles are, themselves, a perfect demonstration of what information gain is supposed to fix. They've analysed the same SERP, found the same angles, and reproduced them in slightly different words. They're consensus content about a concept whose entire point is that consensus content gets you nowhere.
We're going to do something different here.
Yes, we'll cover what information gain is. We'll explain the patent. But the bulk of this article is about something the rest of the SERP completely ignores: how you actually implement information gain as a process — before you write a single word, inside your brief templates, when deciding between creating new content and refreshing old content, and for content types like ecommerce that nobody in this space seems to think about.
If you already know what information gain is and you're here for the how, jump straight to the workflow section. If you want the full picture, start here.
What Information Gain Actually Means (and What It Doesn't)
The Patent in Plain English
In 2018, Google filed a patent. In June 2022, that patent was granted. It's titled "Contextual estimation of link information gain," and it describes a system where Google can score how much new information a piece of content adds for a specific user, relative to the content they've already seen.
The key phrase there is "already seen." The patent isn't measuring whether your content is unique in some abstract, universal sense. It's measuring whether it adds something new to what a particular user has already read during their search session.
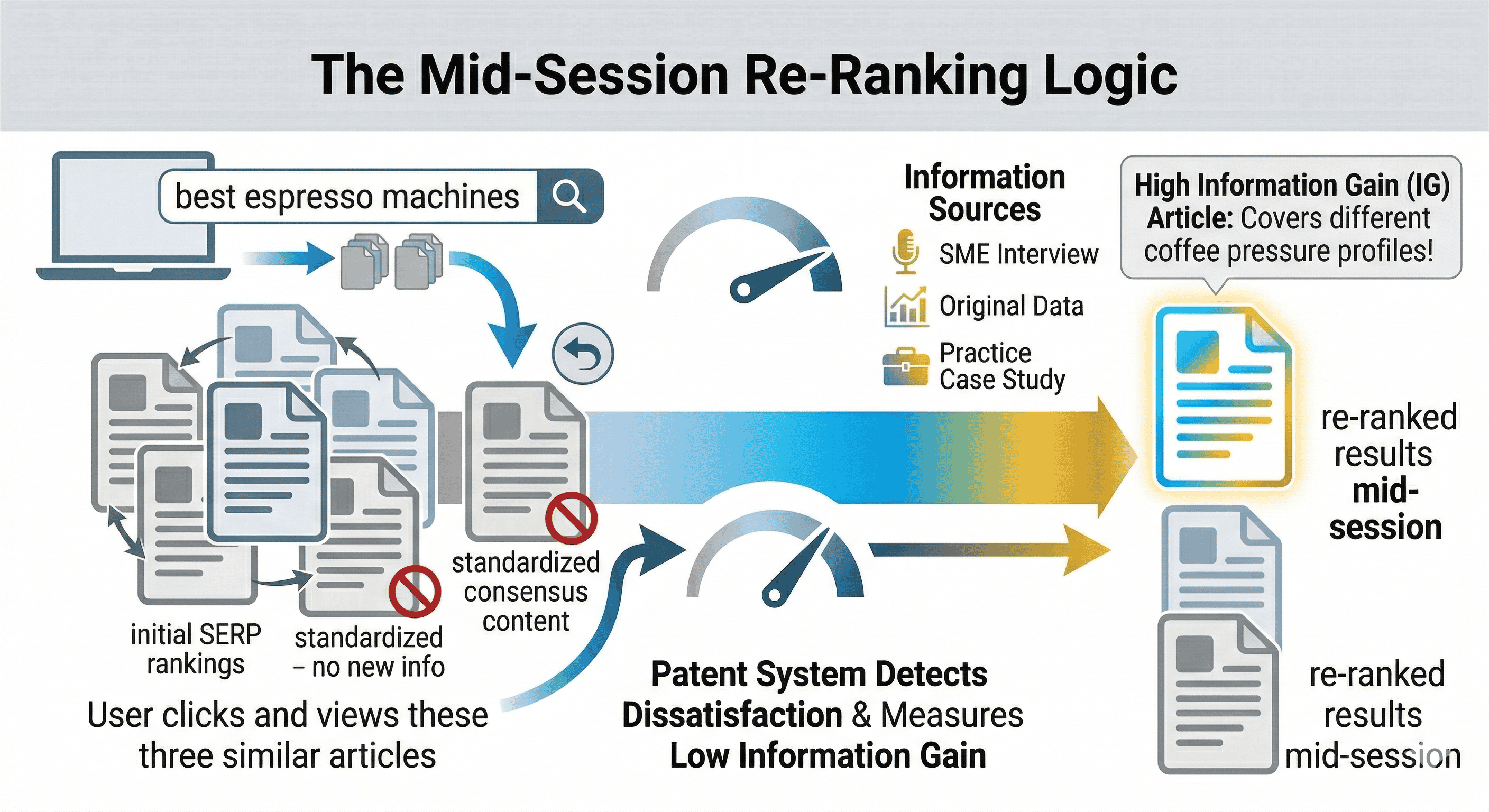
Think of it this way. A user searches for "best espresso machines." They click on three results, skim them all, and get the same list of machines with the same specs. Every article has covered the same ground. If a fourth article appears that covers brew pressure calibration in detail — something none of the first three mentioned — that article has high information gain for that user in that session.
Google's patent describes a scoring mechanism that could, in theory, use that understanding to re-rank results mid-session or prioritise certain documents in secondary searches (searches made after a first search on the same topic).
That's the short version. Here's what it doesn't mean.
The Distinction Everyone Misses: Secondary vs. Primary Results
Most articles talk about information gain as if it's a direct ranking factor that applies to every search. The patent is more specific than that.
The scenarios described in the patent predominantly apply to secondary results — the content Google serves up when a user has already interacted with initial results and either pogo-sticked back, made a follow-up query, or shown signs of dissatisfaction. In those cases, Google could theoretically use information gain scores to surface something genuinely different rather than giving the user the same article again with a slightly different headline.
Whether it also influences primary rankings — your initial position for a query — is less clear. The patent allows for it, and there's decent circumstantial evidence (more on that below), but the patent itself focuses most heavily on that secondary, dynamic re-ranking scenario.
This distinction matters for how you think about strategy. If IG only affects secondary results, the implication is that differentiation helps you when users are already deep in a research session. That's still valuable. Researchers and buyers doing thorough comparison work are often higher-intent. But it changes the urgency calculation compared to "information gain directly determines your ranking for every query."
Is Information Gain a Confirmed Ranking Factor?
No. Google hasn't confirmed it. They also haven't denied it, which is standard behaviour for any patent-based discussion.
There's a counter-argument worth taking seriously here. Roger Montti, writing in Search Engine Journal, notes that the patent's context is "largely automated assistants and chatbots" — meaning the information gain score was designed for sequential dialogue sessions rather than standard web search. He doesn't dismiss it entirely, but his read is that its primary relevance is to AI Overviews and AI-assisted search rather than traditional organic rankings.
Dixon Jones at InLinks disputes the distinction itself. His argument is that it doesn't matter whether the patent was designed for chatbots, because Google's search interface is becoming a chatbot experience anyway — AI Overviews being the obvious evidence. If that's right, the chatbot/search boundary is already dissolving and IG applies regardless of which side of it you're on.
The pragmatic take: you don't need to be certain the information gain score is a direct ranking signal to benefit from optimising for it. The core behaviour it rewards — content that adds something no existing result contains — is the same behaviour that earns backlinks, builds topical authority, gets cited in AI Overviews, and satisfies Google's stated preferences for original, experience-first content. Whether or not there's a specific score attached to it, the underlying principle is sound.
Why Information Gain Matters More Now Than When the Patent Was Filed
AI Overviews Changed the Incentive Structure
When AI Overviews launched in search results, they changed what ranking actually means. Getting position one no longer guarantees clicks. In many cases, the AI Overview absorbs the query and the user never goes further.
But here's what's interesting about how AI Overviews are built. Google's own documentation on how its generative search features work makes clear that the system doesn't just pull from the top-ranked documents for a query. If the top results are too similar, it actively looks further afield — at documents surfaced by related queries — specifically to find diversity of information.
That's information gain logic applied to answer synthesis. Content that covers unique ground isn't just more likely to rank. It's more likely to be cited in the AI Overview, which is a different and increasingly valuable kind of visibility.
The practical implication: if your content says what everything else says, an AI Overview won't need you. It can pull that consensus information from existing sources. But if you have something none of the others have — a specific dataset, a practitioner process, a well-argued contrarian take — you become useful to the synthesis, not redundant to it.
The Consensus Content Collapse
There's a structural problem in how most SEO content gets made.
The brief goes to a writer. The writer researches the topic by reading what ranks. The content reflects what ranks. You end up with an article that closely mirrors the SERP it was designed to beat, dressed up in slightly different words and expanded by 20%.
This was a reasonable strategy for a while. Then AI got very good at exactly this kind of content production, at scale, for free. Large publishers and content farms can generate this stuff faster than any team can. Competing on volume alone is a losing game if anyone with an API key can play it.
The only thing AI genuinely can't generate is information it doesn't have. Your first-hand experience running campaigns. Your client data. Your opinion formed after watching something play out differently to how every guide said it would. That's the gap information gain occupies — and it's a gap that matters more every month.
What This Means for Smaller Sites and Agencies
There's actually good news buried in this for smaller operations.
Under the old model, domain authority was close to everything. If you had links, you ranked. If you didn't, you probably didn't. Information gain doesn't eliminate that relationship — a high-authority site with strong information gain content is still formidable — but it does create genuine openings for smaller sites that bring something specific.
An agency that publishes a piece containing real campaign data, or a manufacturer that documents their production process in detail nobody else can access, has something that none of the bigger sites has. The information is theirs alone. If it maps to real search intent and is packaged well, it can compete.
Budget and domain age don't fully determine outcomes here the way they do everywhere else. That's a real opening if you know what to do with it.
How to Measure Information Gain Before You Publish
This is the section nobody writes. Every article tells you to "add original content" but doesn't give you a process for working out what's original, what's consensus, and what qualifies as worth adding.
Here's a four-step approach you can actually run before drafting anything.
Step 1: Run a SERP Entity Audit
Pull up the top 10 results for your target query and go through each one. You're not reading for enjoyment — you're mapping what's there.
For each article, note:
- The primary claim it makes about the topic
- The key entities it covers (specific terms, concepts, named things)
- Any data, figures, or specific examples it uses
- The framing angle (is this a definition? A how-to? A comparison?)
Do this across all 10 results and you'll start to see patterns. Certain claims appear in every article. Certain examples get recycled. Certain entities appear across the SERP but with thin coverage — mentioned but not explored.
You're building a map of the consensus zone versus the underserved zone.
Step 2: Identify the Consensus Loop
Once you've done the audit, list out the claims and topics that appeared in five or more of the top 10 results. These are your zero-IG zones.
For information gain in SEO, the consensus loop looks like this:
- Google has a 2022 patent about content uniqueness
- The skyscraper technique is being replaced by a differentiation approach
- Original data and expert quotes are the main tactics
- This connects to E-E-A-T
- AI-generated content makes uniqueness more important
If your planned article primarily covers these things, you're contributing nothing to the topic. You're padding the consensus. Your IG score — formal or informal — is low.
This step forces you to confront an uncomfortable question before you invest in content: is the angle I was planning to write already saturated?

Step 3: Score Your Planned Angles
For each angle or section you're planning to include, score it on three things:
Novelty — Is this covered in the top 10? If yes, is your treatment meaningfully different (deeper, more specific, with unique evidence), or is it effectively the same information? Score 1–5.
Query alignment — Does this angle map to something people are actually searching for or asking? Would a real user care about this? Score 1–5.
NLP visibility — Can this be expressed as a clear entity-attribute pairing that a machine can parse? "Information gain [workflow] [for content briefs]" is clean. "The interesting nuance of how uniqueness works in practice" is not. Score 1–5.
Add the three scores. Anything below 9 should either be cut or reworked until it scores higher. Anything 12 and above is genuinely worth writing.
This isn't a perfect science. But having a scoring conversation with yourself or your team before writing saves a lot of wasted effort on content that lands without impact.
Step 4: Identify Where Your IG Is Coming From
If you've identified gaps worth filling, the next question is: what's your source?
There are four realistic sources of information gain. Be honest about which one you're using.
Proprietary data. You have information nobody else has — internal campaign results, client benchmarks, survey data you ran, original research. This is the strongest possible IG source because it's inherently non-replicable. No one else can publish it.
First-hand experience. You've done the thing. You've run the campaign, tested the approach, seen what actually happened compared to what the guides predicted. This isn't data-based but it's real and it's yours. Use specific examples. Vague "in my experience" claims don't count — specificity is what makes experience-based content credible.
SME extraction. You have access to people with knowledge the internet hasn't captured yet. An internal product specialist, a client who's an expert in their field, a supplier who knows their industry inside out. If you can get them talking and document what they know, that's IG the rest of the SERP can't access.
Contrarian framing. You've looked at the consensus and you disagree with it, or you've identified a nuance that changes the picture. This is riskier because you need to back it up, but a well-argued counter-position on a settled topic is some of the most linkable content in any niche.
Be wary of a fifth approach: reframing. Taking existing information and presenting it in a different structure (same claims, different format) isn't really information gain. It might improve user experience, but it doesn't add to the corpus in the way the patent describes.
How to Build Information Gain Into Your Content Workflow
Embedding IG Into Your Brief Template
Most content briefs contain: target keyword, word count, H2 structure, competitor references. That's about it for the majority of agencies and in-house teams.
None of that forces the writer to think about what's unique about this piece. You can produce a perfectly competent brief following that format and end up with a piece that's technically accurate, well-structured, and entirely indistinguishable from what already ranks.
Here's what a brief template looks like with IG baked in:
Target query: [primary keyword] Target entity: [main subject — be specific] Search intent stage: [awareness / consideration / decision] Word count target: [range]
Consensus claims to avoid (things every top-10 article already covers — do not repeat these as if they're original)
- [claim 1]
- [claim 2]
- [claim 3]
IG sources for this piece (where is our unique information coming from?)
- [data source / internal reference / SME name / contrarian angle]
Target IG angles (what specific things will this piece cover that don't exist in the top 10?)
- [angle 1 — entity + attribute it covers]
- [angle 2]
- [angle 3]
IG score per angle (novelty + query alignment + NLP visibility)
Schema target: [Article / HowTo / FAQ / combination] Internal links out: [target pages with descriptive anchor text] PAA targets: [specific questions to answer within the piece]

The "consensus claims to avoid" field is the one that changes behaviour most immediately. Writers default to researching the topic by reading what ranks. If you explicitly tell them which claims are already saturated, they stop reproducing them as if they're novel and start focusing on what isn't covered.
The "IG sources" field forces accountability. If someone fills it in with "I'll do SERP research," that's a signal the piece won't have real information gain. If it says "Q3 campaign data from client X" or "interview booked with [person] on [date]," there's an actual plan.
SME Extraction: Getting IG from People, Not Search Results
This is the most underused IG source, and it's the one with the highest ceiling for most businesses.
Every organisation has internal expertise that's never been published. Specialists who've been doing something for years and have developed opinions, processes, and pattern recognition that no amount of SERP research will give you access to. That knowledge is sitting there, generating nothing for the site.
The problem is getting it out. Most specialists aren't writers, don't have time to write, and aren't particularly interested in explaining what they do for a blog post. You need a process that minimises the ask on their end and maximises what you can extract.
Here's a framework that works in practice:
The interview takes 20–30 minutes. That's the commitment you're asking for.
Prepare 5–7 questions in advance. These aren't generic "what do you do" questions — they're targeted at the specific topic the content will cover. The goal is to surface experiences, opinions, and process details that aren't in any existing resource.
Questions that tend to produce IG:
- "What's the thing about [topic] that you think is wrong or overstated in most guides?"
- "What do you do in practice that you'd never see in a textbook or article about this?"
- "What mistake do you see clients or customers make repeatedly that you think is underappreciated as a problem?"
- "What would you do differently about [topic] if you were starting from scratch today?"
- "What has surprised you most about [topic] in the last year or two?"
Record the conversation (with permission). Transcribe it. You'll usually find two or three moments where the specialist says something specific and non-obvious — that's your IG content. Build the article around those moments rather than using them as decoration around a standard structure.
A quick example of what this looks like in practice.
We ran this process for a client in the coffee industry. The brief was for an article about decaf processing methods. Standard SERP research gave us the usual: Swiss Water Process, CO2 method, solvent-based methods. Every article covers these in roughly the same way.
The roaster we interviewed mentioned something no article we'd found covered in any depth: the relationship between decaf roast profiling and the different moisture content of decaffeinated beans, and how most roasters use the same profile for decaf and regular beans as a result. That's a specific, technical insight that a buying audience interested in coffee quality would find genuinely useful — and it came from 20 minutes of conversation, not SERP research.
That kind of detail came from someone who's actually doing the thing. Twenty minutes of conversation, not SERP research.
Information Gain for New Content vs. Content Refreshes
These are different problems, and they need different processes. Most articles about IG treat them as the same, which leads to wasted effort.
For new content, IG analysis happens at the planning stage. You're asking: is there a genuine gap in the SERP that we can fill with something we actually have? If the answer is no — if every angle you'd cover is already well-served and you don't have a proprietary source — the right call is often not to publish at all, or to wait until you do have a source. Publishing consensus content isn't neutral. It contributes to the problem the patent is trying to solve.
For content refreshes, the IG question is different. You're asking: has our existing content lost its edge? Has the SERP moved around it? Are the entities and attributes we originally covered now standard across the top 10, leaving us with no differentiation?
The signals that tell you a refresh is needed from an IG perspective:
- Rankings have slipped despite no obvious technical issues
- The content you're tracking has gone from ranking above similar articles to ranking alongside them
- Google Search Console shows impression growth but click decline (the AI Overview is answering the query without needing to send users to you)
- The claims in your article are now standard across the SERP — you've been absorbed into the consensus
For a refresh, your IG analysis starts with your own page rather than the SERP. Identify which sections are now consensus content. Cut or compress them. Then identify what new information you can add. This is where fresh proprietary data or a new SME interview pays off particularly well — you're injecting new IG into an existing piece that already has some ranking history.
The refresh workflow isn't just "update the stats and republish." It's closer to: strip out what's been absorbed by the consensus, identify new gaps, fill them with something you actually have, then republish.
Information Gain for Different Content Types
Editorial and Blog Content
This is the default application most articles describe, so we'll keep it brief. Editorial content — long-form articles, guides, explainers — is the most natural home for IG thinking. You have space to go deep, structure for detailed entity coverage, and flexibility to include data, interviews, and case-based examples.
The one thing to add that's underexplored: IG in editorial content has to be distributed through the piece, not dumped in a single section. A 3,000-word article where 2,800 words are consensus content and 200 words are genuinely unique isn't a high-IG piece. The uniqueness needs to run through it — different H3 sections making different specific points that aren't replicated across the SERP.
eCommerce Content
Nobody in the information gain conversation talks about ecommerce. This is a gap worth paying attention to.
eCommerce content has some specific IG challenges:
Product pages are constrained by what's on the product. You can't wildly differentiate a spec page for a component that has standard specs. But you can add IG through: real usage context (what does this product do in situations your competitors' descriptions don't mention?), customer outcome data, compatibility details not covered elsewhere, and edge case coverage.
A product page that says "this machine produces espresso at 9 bar pressure" is consensus. A product page that explains why 9 bar is the standard, what happens at 15 bar (which sounds better but often isn't), and which bean roast profiles benefit from adjustable pressure — that's an IG-rich product page. It adds something the manufacturer's spec sheet and every competitor page doesn't.
Category pages are interesting because they're often treated as pure navigation, with minimal content. The IG opportunity on a category page is in the buyer education layer: what do buyers in this category consistently get wrong? What should they know before comparing products? What question does everyone ask that no category page in your niche answers well?
Answer those things specifically — not with generic "here's what to consider" filler, but with the actual answer — and your category page stops being an SEO boilerplate exercise and starts being genuinely useful.
Buying guides are where IG is most achievable in eCommerce, and where it's most often squandered. The standard buying guide format (here are the key factors to consider; here are our top picks) is one of the most replicated content structures on the web. To generate IG in a buying guide, you need specific data. Real price comparisons with recent dates. Actual product testing observations. Customer review analysis that surfaces patterns nobody else has documented. Failure modes of specific products from real usage.
If your buying guide could have been written by anyone with access to the product listings and a few competitor articles, it has no information gain.
B2B and Agency Content
For agencies and B2B service providers, IG is both easier and harder than it looks.
Easier because the asset is already there: you have campaign data, client outcomes, process methodologies, and pattern recognition across clients and industries. That's genuinely proprietary. Nobody outside your agency has it.
Harder because most agencies are understandably cautious about sharing it. Client confidentiality is real. Case study approval processes are slow. The temptation is to write about processes in the abstract rather than grounding them in specifics.
The middle path: aggregate data across clients, anonymise where needed, but keep the numbers. "In our experience, X tends to happen" is zero-IG. "Across the 14 ecommerce sites we migrated to Shopify in 2026, organic traffic recovery averaged 11 weeks, with the fastest recovery (4 weeks) in sites that had clean URL redirect mapping pre-migration" — that's IG. It's specific. It's from a source nobody else has. It maps to real search intent from people researching platform migrations.
You don't need to name the clients. You need to name the numbers.
What Bad Information Gain Looks Like
This might be the most useful section for avoiding wasted effort.
Uniqueness Without Relevance
Clearscope has a good example of this: adding references to Ferrari and Lamborghini to an article about SEO would technically add novel information, but it's information the user didn't come for and can't use. It would increase the document's differentiation from other SEO articles without improving its information gain in any meaningful sense.
The principle applies broadly. Adding a long section about the history of information theory to an article about information gain in SEO is technically novel. Nobody else is going deep on Peter Pirolli's 1999 book in this context. But a user searching for how to implement IG in their content workflow doesn't need it, and it dilutes the piece.
IG that isn't relevant to query intent isn't just unhelpful — it can actively confuse the signal you're trying to send about what the page is for.
Novelty That Misses the Intent Stage
There's a version of this that's subtler and catches out a lot of good-faith attempts at IG content.
You identify a genuine gap in the SERP. You write something nobody has covered. But the gap you identified is at the wrong stage of intent for the query you're targeting.
For "information gain in SEO" — a broadly informational query — adding deep technical analysis of the patent's ML implementation specifics is novel but misaligned. Most people at that query stage aren't ready for that level. They'll bounce. The content gets impressions, doesn't get clicks, and if it does get clicks, it gets short dwell times.
The fix is to match your IG angle to the intent stage before writing. Ask: what does a user at this stage of understanding actually need to know that they can't find elsewhere? That's different from: what's interesting that hasn't been covered?
Rebranding Consensus as Insight
This is the most common failure mode and the hardest to self-diagnose because it feels like differentiation while you're doing it.
You read the SERP. You note that everyone talks about "original data" as the IG tactic. You decide to frame it differently: "proprietary intelligence" or "first-party insight signals." You build a section around this. It has a different structure and vocabulary. It's technically not the same words.
But it's the same information. Calling it something else doesn't add to the corpus — it just changes the surface pattern. This is the content equivalent of using synonyms to avoid plagiarism detection. The idea hasn't changed.
Genuine IG is about the information, not the expression of existing information. If removing your unique framing leaves you with the same point everyone else is making, the framing isn't IG.
FAQs — Information Gain in SEO
What is information gain in SEO?
Information gain refers to the additional, unique information a piece of content provides beyond what a user has already seen on a topic. Google's 2022 patent describes a scoring system that measures this uniqueness, potentially using it to surface more diverse results when a user appears unsatisfied with initial search results.
Is information gain a confirmed Google ranking factor?
No. Google has neither confirmed nor denied that the information gain score directly influences rankings. The patent exists and was granted, but patents frequently describe systems that are never implemented. The circumstantial case for it mattering — the timing of helpful content updates, AI Overview behaviour, Google's public statements on original content — is reasonable but not definitive.
How is information gain different from topical authority?
Topical authority describes how comprehensively a site covers a subject area overall. Information gain describes how much unique value a specific piece of content adds relative to what already exists. You can have topical authority built from consensus content, but you'll have a harder time maintaining it as the SERP matures. The two concepts work best together: authority from depth and breadth, IG from specificity and uniqueness within that coverage.
Can AI-generated content have information gain?
Technically yes, but practically it's rare. AI generates content based on patterns in existing data. It can recombine, summarise, and structure consensus information well. It can't surface proprietary data, first-hand experience, or expert knowledge that isn't already in its training set. Those are the primary IG sources. Where AI-generated content tends to cluster is in the zero-IG zone: well-written, accurate, and entirely redundant.
What's the difference between information gain and the skyscraper technique?
The skyscraper technique optimises for coverage — making your piece more comprehensive than what ranks. The assumption is that comprehensiveness wins. Information gain optimises for differentiation — making your piece say something none of the others do. These aren't always opposed, but they produce different content strategies. Skyscraper logic pushes you to cover everything. IG logic pushes you to identify what's missing and cover that specifically, even if you leave consensus territory alone.
How do I add information gain to existing content?
Run your existing piece through the SERP audit described in this article. Identify which sections are now consensus. Check whether the data or examples you originally used have since been replicated across the SERP (this happens faster than you'd think). Then find your IG source for the refresh: new data, a fresh expert interview, or a contrarian angle that's developed since you first published. Compress or remove the sections that have become redundant. Build out the new material. Republish with an updated date and log the changes.


Get in touch today
complete the form below for an informal chat about your business


We are a small, but perfectly formed, Digital Marketing Agency based in Stoke-on-Trent, Staffordshire. We provide services that help business owners make more money online.